5 Data Granularity Mistakes That May Cost You
How closely should you look at your data to maximize returns?
In the age of big data, the challenge is no longer accessing enough data; the challenge is figuring out the right data to use. In a past article, I focused on the value of alternative data, which is a vital business asset. Even with the benefits of alternative data, however, the wrong data granularity can undermine the ROI of data-driven management.
We’re so obsessed with data, we forget how to interpret it.
— Danah Boyd, Principal Researcher at Microsoft Research
So how closely should you be looking at your data? Because the wrong data granularity could cost you more than you realize.
Understanding data granularity
Simply put, data granularity refers to the level of detail of our data. The more granular your data, the more information contained in a particular data point. Measuring yearly transactions across all stores in a country would have low granularity, as you would know very little about when and where customers make those purchases. Measuring individual stores’ transactions by the second, on the other hand, would have incredibly high granularity.
The ideal data granularity depends on the kind of analysis you are doing. If you are looking for patterns in consumer behavior across decades, low granularity is probably fine. To automate store replenishment, however, you’d need much more granular data.

When you choose the wrong granularity for your analysis, you end up with less accurate and less useful intelligence. Think about how messy weekly store replenishment based only on yearly systemwide data would be! You’d continuously experience both excess stock and stockouts, amassing huge costs and high levels of waste in the process. In any analysis, the wrong data granularity can have similarly severe consequences for your efficiency and bottom line.
So are you using the correct data granularity for your business intelligence? Here are five common — and costly — data granularity mistakes.
1. Grouping multiple business trends into a single pattern (when data isn’t granular enough).
Business intelligence needs to be clear and straightforward to be actionable, but sometimes in an attempt to achieve simplicity, people don’t dive deep enough into the data. That’s a shame because you will miss out on valuable insights. When data granularity is too low, you only see large patterns that arise to the surface. You may miss critical data.
In far too many cases, not looking closely enough at your data leads to compressing disparate trends into a single result. Businesses making this mistake end up with uneven results. They are more likely to have unpredictable and extreme outliers that don’t fit the overall pattern — because that pattern doesn’t reflect reality.
This is a common problem in many traditional supply chain forecasting systems. They can’t handle the level of granularity necessary to predict SKU-level demand in individual stores, which means that a single store may be dealing with both overstocks and stockouts at the same time. Automated systems powered by AI can handle the complexity required to properly segment data, which is one reason these improve supply chain efficiency. Sufficient data granularity is critical to more accurate business intelligence.
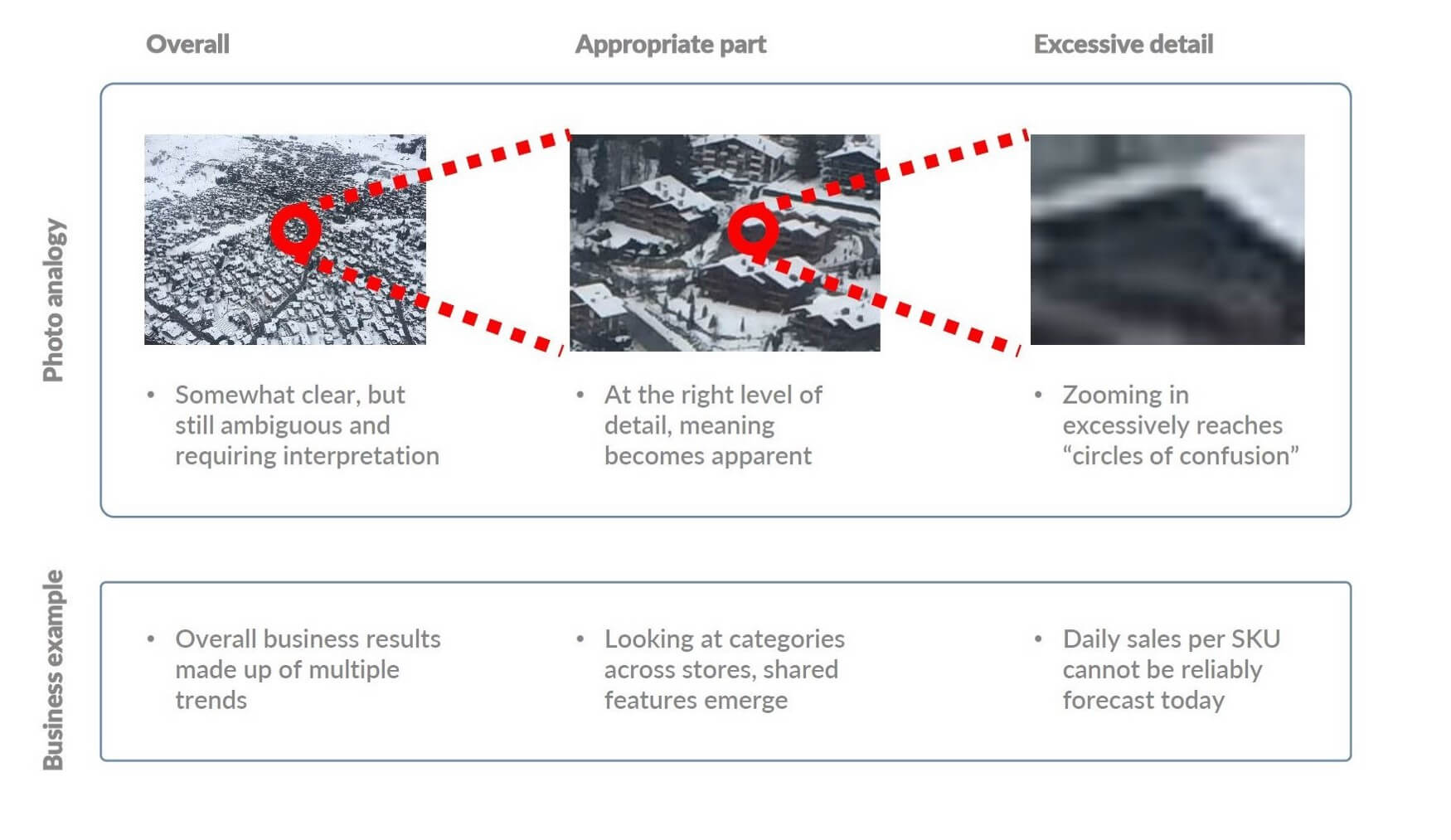
2. Getting lost in the data without a point of focus (when data is too granular).
Have you ever accidentally zoomed way too far into a map online? It’s so frustrating! You can’t make out any useful information because there’s no context. That happens in data, too.
If your data is too granular, you get lost; you can’t focus enough to find a useful pattern within all the extraneous data. It’s tempting to feel like more detail is always better when it comes to data, but too much detail can make your data virtually useless. Many executives faced with so much data find themselves frozen with analysis paralysis. You end up with unreliable recommendations, a lack of business context, and unnecessary confusion.

Too granular data is a particularly costly mistake when it comes to AI forecasting. The data may trick the algorithm into indicating that it has enough data to make assumptions about the future that is not possible with today’s technology. In my supply chain work at Evo, for example, it’s still impossible to forecast daily sales per SKU. Your margin of error will be too large to be useful. This level of granularity undermines goals and diminishes ROI.
3. Not choosing the granularity of time variables purposefully.
The most common data granularity mistakes are related to time intervals, i.e., measuring variables on an hourly, daily, weekly, yearly, etc. basis. Temporal granularity mistakes often occur for convenience’s sake. Most companies have standard ways to report timed variables. It feels like it would require too much effort to change them, so they don’t. But this rarely is the ideal granularity to address the problem analyzed.
When you weigh the cost of changing the way your system reports KPIs versus the cost of consistently getting inadequate business intelligence, the benefits of purposefully choosing the right granularity register. Depending on the granularity of time, you will recognize very different insights from the same data. Take seasonality trends in retail, for instance. Looking at transactions over a single day could make seasonal trends invisible or, at the very least, contain so much data that patterns are just white noise, while monthly data shares a distinct sequence you can actually use. If standard KPIs skip monthly reporting to go straight to quarterly patterns, you lose valuable insights that would make forecasts more accurate. You can’t take time granularity at face value if you want to get the best intelligence.
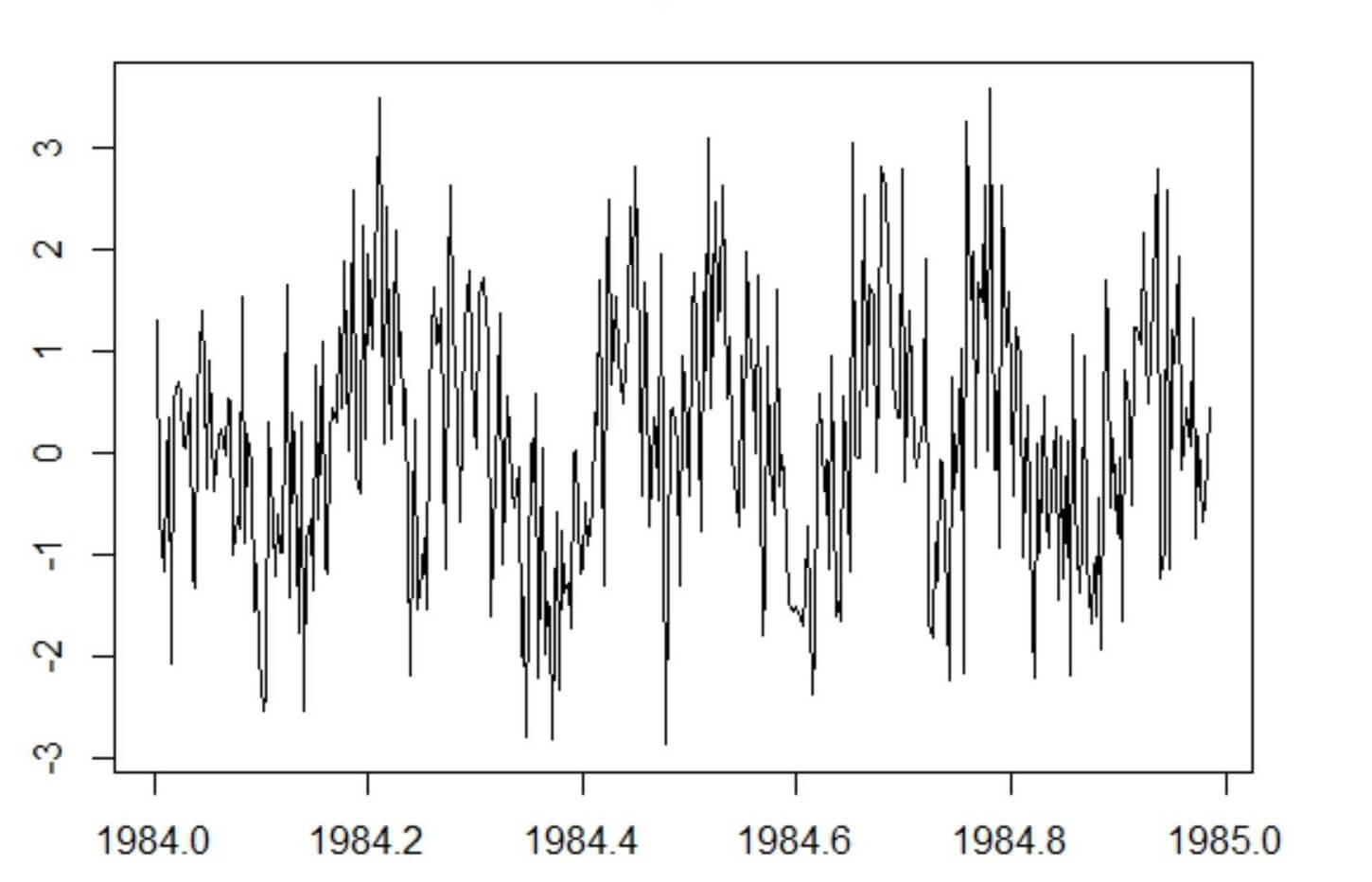
Daily seasonality (Source: http://r-tutorials.com/r-exercises-41-50-working-time-series-data/)
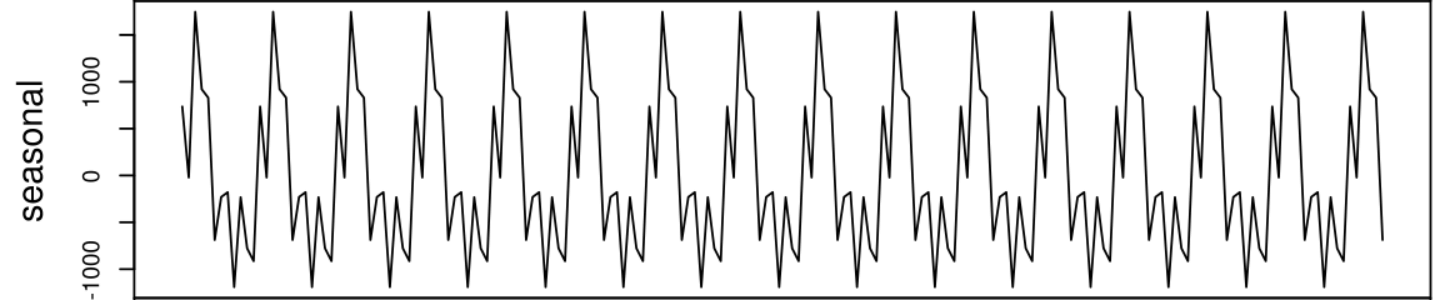
Yearly seasonality (Source: https://commons.wikimedia.org/)
4. Overfitting or underfitting your model to the point that the patterns you see are meaningless.
AI models need to generalize well from existing and future data to deliver any useful recommendations. Essentially a good model could look at this data:
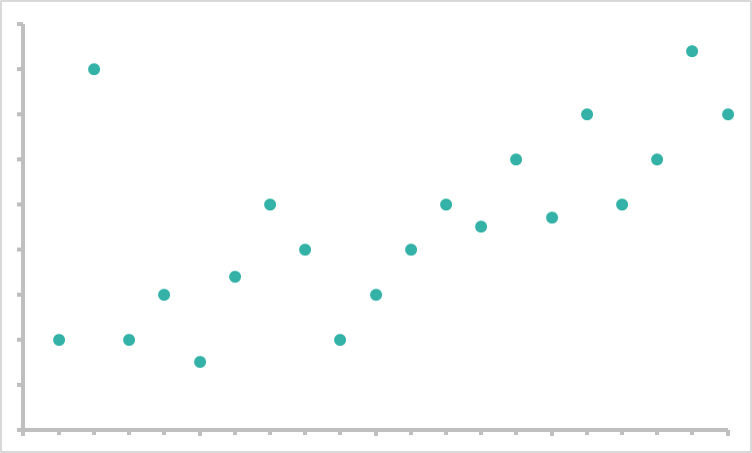
And assume this as a working model based on the information:
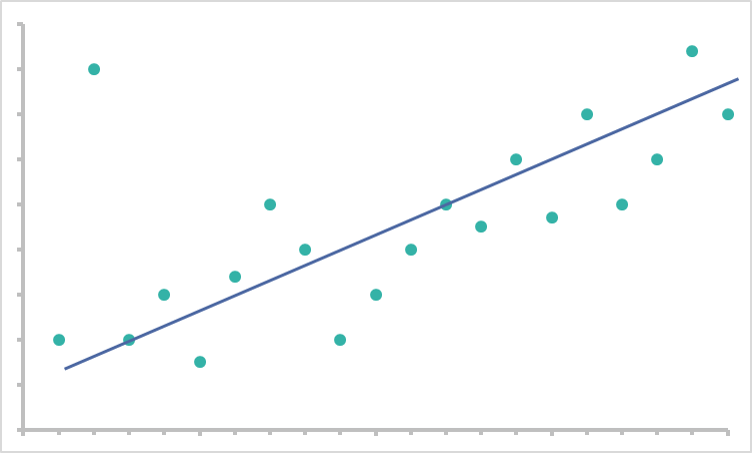
The pattern may not perfectly represent the data, but it does a good job predicting typical behavior without sacrificing too much intelligence.
If you don’t have the right data granularity, however, you can end up with the wrong model. As we talked about before, overly granular data can cause noise that makes finding a pattern difficult. If your algorithm consistently trains with this noisy detail level, it will deliver noise in turn. You end up with a model that looks like this:
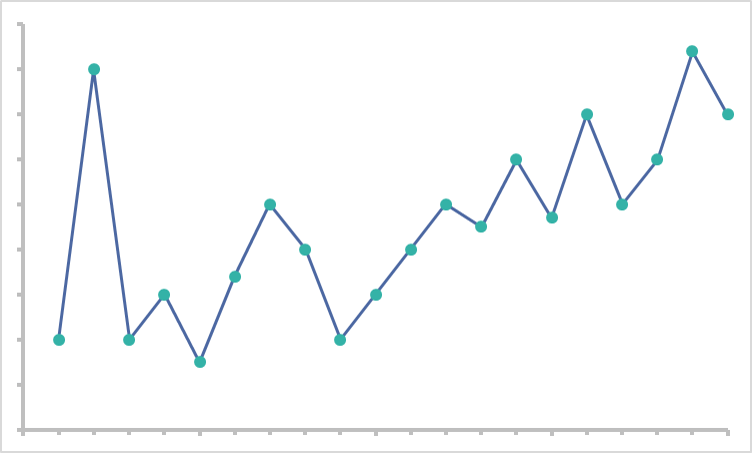
We call this overfitting your model. Every data point has an outsized impact, to the extent that the model cannot generalize usefully anymore. The problems initially caused by high granularity are magnified and made a permanent problem in the model.
Too low data granularity can also do long-term damage to your model. An algorithm must have sufficient data to find patterns. Algorithms trained using data without enough granularity will miss critical patterns. Once the algorithm has moved beyond the training phase, it will continue to fail to identify similar patterns. You end up with a model that looks like this:
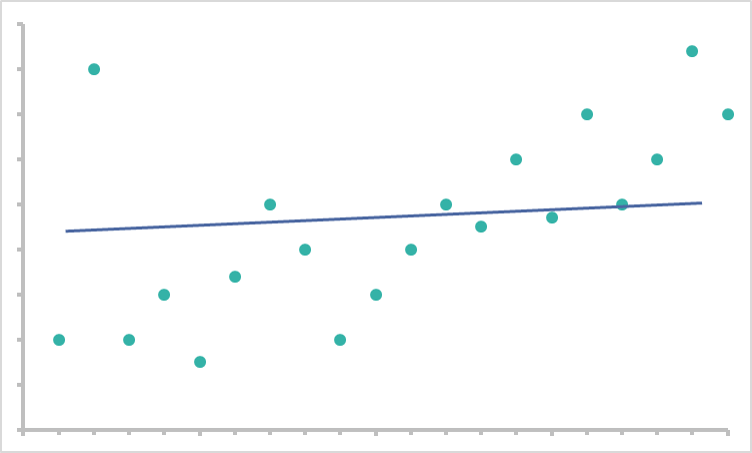
This is underfitting the model. The algorithm comes close to making the right predictions, yet they will never be as accurate as they could have been. Like overfitting, it is a magnification of the initial granularity problem.
When you are creating a model for your analysis, proper granularity becomes exponentially more important than once you have a stable algorithm. For this reason, many companies choose to outsource this part of the process to experts. It’s too delicate and costly a stage for mistakes.
5. Adjusting the granularity of the incorrect data entirely.
Perhaps the costliest data granularity mistake merely is focusing so much on optimizing the granularity of KPIs you currently measure that you fail to realize they are the wrong KPIs entirely. We aim to achieve the correct data granularity not to optimize any specific KPI performance but rather to recognize patterns in the data that deliver actionable and valuable insights. If you want to improve revenue, for example, you may be undermining your success by only looking at patterns in pricing. Other factors are involved.
Take an example from my colleague. A new Evo client wanted to increase sales, and an initial test applying our Supply Chain tools showed a 10% improvement in less than two weeks. Our CEO was beyond excited by these unprecedented results, but to his surprise, the supply chain manager was not impressed. His primary KPI was product availability, and according to internal numbers, that had never changed. His focus on improving a particular KPI came at the cost of recognizing valuable insights from other data.
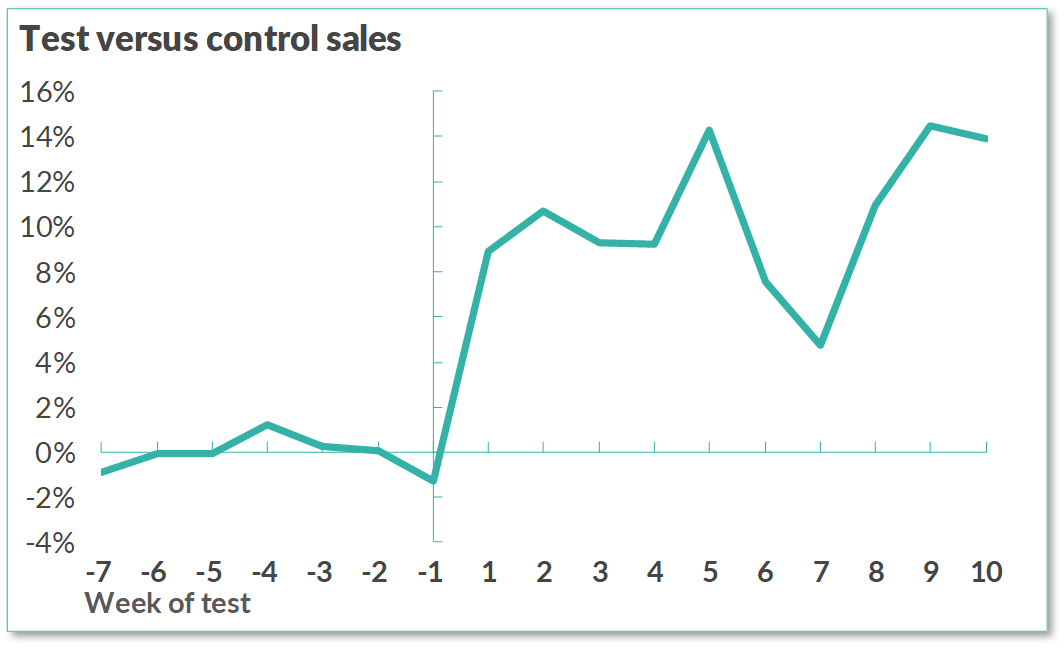
Testing a new supply chain system (image by Fabrizio Fantini)
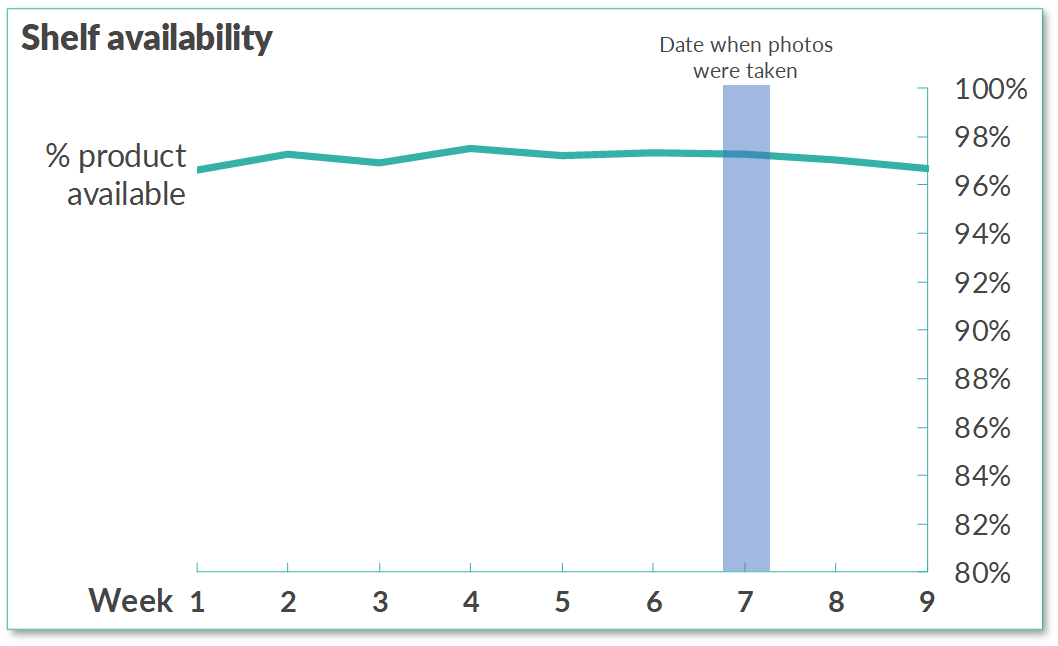
Product availability after the test (image by Fabrizio Fantini, CC with attribution)
Whether or not that KPI was accurately measured, focusing entirely on changing its performance held this manager back from seeing the value in a new approach. He was a smart man acting in good faith, but the data misled him — an incredibly common yet expensive mistake. Correct data granularity is vital, but it can’t be a goal in and of itself. You have to look at the bigger picture to maximize your returns from AI. How closely you look at your data won’t matter if you don’t have the right data in the first place.
A common fallacy of data-driven management is using the wrong data to answer the right question.”
— Fabrizio Fantini, Founder and CEO of Evo
The benefits of the right data granularity
There’s no magic bullet when it comes to data granularity. You must choose it carefully and intentionally to avoid these and other less common mistakes. The only way to maximize returns from your data is to look at it critically — usually with an expert data scientist’s help. You likely won’t get granularity right on your first try, so you need to test and adjust until it’s perfect.
It’s worth the effort, though. Looking closely, but not too closely, your data ensures optimal business intelligence. Segmented and analyzed correctly, data transforms into a competitive advantage you can count on.
***
Big thanks to Kaitlin Goodrich.





